
La app ‘Preven Game’ es una aplicación de Prevención de Riesgos Laborales que facilita el aprendizaje a los usuarios sobre los riesgos en las distintas profesiones de una manera lúdica y entretenida.
La aplicación pone a prueba los conocimientos en prevención de riesgos laborales que existen en más de 20 profesiones diferentes recogiendo un total de 40 riesgos laborales como atropellos, caída de objetos, choques y golpes, cortes y heridas, contacto dérmico con disolventes o realización de movimientos repetitivos. Dicha aplicación es gratuita y está disponible tanto para iphone como para android.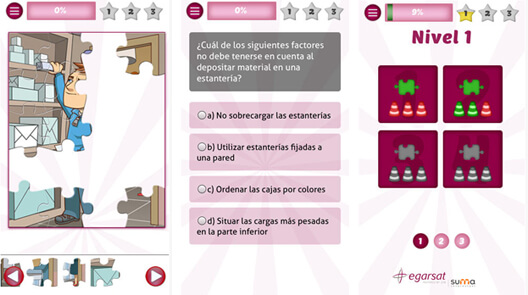
Raquel Sellarès, jefa del departamento de prevención de Egarsat, resalta la eficacia de este tipo de formato .“Sin apenas esfuerzo, gracias a su vertiente lúdica, la app favorece que el usuario quiera seguir poniendo a prueba sus conocimientos a medida que va utilizando la aplicación”.
La app incluye cerca de 100 preguntas distribuidas en tres niveles de dificultad, y permite crear y almacenar diferentes perfiles, para que varias personas con el mismo terminal móvil puedan guardar sus progresos. El usuario también puede borrar el registro de puntuación y empezar otras partidas con nuevas preguntas que aparecen aleatoriamente.
Para superar toda la secuencia, el usuario debe realizar 10 puzzles y contestar un total de 36 preguntas. A medida que se va progresando, la app va mostrando el avance en el porcentaje de conocimiento adquirido en cada nivel y, al finalizar, permite compartir el resultado en redes sociales.











